.png)
Looker studioとBigqueryを使ってA/Bテストをトラッキングするには?
Looker studioとBigqueryを使ってA/Bテストをトラッキングするには?
.webp)
BigQueryを使用してA/Bテストを監視するためのLooker Studioダッシュボードを作成します。
この記事では、A/Bテストのトラッキング専用のLooker StudioダッシュボードをBigQuery経由で統合して設定する手順を説明します。

内容
BigQueryを使用してA/Bテストを監視するためのLooker Studioダッシュボードを作成します。
- 背景と目的
- BigQueryと分析ツールでA/Bテストをトラッキングするための前提条件は何ですか? ?
- A/Bテストツールの接続手順
- 分析ツールをBigQueryに接続する手順
- BigQueryでA/Bテストデータを活用する
- Looker StudioでA/Bテストのモニタリングダッシュボードを作成する
背景と目的
目的は何ですか?
Looker Studioのダッシュボードを作成し、BigQueryを使用してA/Bテストデータを監視することで、高度なデータビズによって 決定的な 洞察を得ることができます。
私たちのダッシュボードのようにダッシュボード - ABテスト - Welyft
BigQueryとは?
BigQueryは、大量のデータを迅速に保存、処理、分析するために設計されたGoogleのクラウドサービスである。
詳しくは以下のリンクを参照されたい:
BigQueryを使うメリットは何ですか?
BigQueryは、プログラムされたSQLクエリを実行することで A/Bテストの モニタリングを自動化し、 分析ツールから 受信した生データ(集計されていないすべてのデータ)を直接処理することで、正確でパーソナライズされた計算を可能にします。
特定の分析ツールの限界?
特定の分析 ツールと Looker Studio 間のコネクタを使用することには欠点もあります:
- サンプリング
- 高度な計算ができない(アップリフト、ダウンリフト、統計的信頼度)
サンプリングは、結果を不正確にしたり、歪めたりする可能性がある。A/Bテストの状況で、バリエーションのパフォーマンスが似ている場合、あるバリエーションを勝者と誤って指定し、誤った決定を導く可能性がある。
そのため、私たちはBigQueryを:
- オートメーション
- サンプリングは避ける
- アップリフト、ダウンリフト、統計的信頼度の計算
なぜA/BテストとBigQueryが直結したアナリティクスツールを選ぶのか?
ほとんどのA/BテストツールはBigQueryとの統合を提供していないか、ベータ版の段階であるため、BigQueryをA/Bテストデータに使用することはできません。
BigQueryを使用したA/Bテストを監視するためのLooker Studioダッシュボードを作成するためのフレームワークと目的ができました。では、このチュートリアルの前提条件を見ていきましょう。
BigQueryと分析ツールでA/Bテストをトラッキングするための前提条件は何ですか? ?
BigQueryとアナリティクス・ツールでA/Bテストをトラッキングするには、..:
- アナリティクスアカウント(GA4、ピアノ、マトモ)
- BigQueryの有効な課金アカウントを持っている
- A/Bテスト ツールと 分析ツール 間のアクティブな接続
- A/Bテストキャンペーン実施中
- A/Bテストキャンペーンのデータを分析ツールに送信します。
- BigQueryのクエリはSQL言語を使って設定するため、SQLの知識がないと設定が複雑になります。
加えて、GCPのためのすべての手配をセットアップするため、プロセスに時間がかかる可能性があること、分析抽出からデータを受信するまでの時間、SQLクエリを準備するための時間、1日か2日(待機時間)を許容することに留意すべきである。
次に、BigQueryを使用してA/BテストをトラッキングするためのLooker Studioダッシュボードを作成するチュートリアルに進みます。
このチュートリアルでは、分析ツールの例としてGA4を、A/Bテストツールの例としてKameleoonを使用します。
A/Bテストツールの接続手順
A/Bテスト・キャンペーンを分析ツールにどのように接続しますか?
GA4とKameleoonを使用した例では、A/Bテストツールを分析ツールに接続する方法を見ていきます。
- Kameleoon インターフェースにログオン します: https://app.kameleoon.com/integrations/dashboard.
- 管理]、[統合]、[ GA4のインストール]の順に進み、 ドメインと ツールの設定 (GTMまたはGtag)を選択します 。
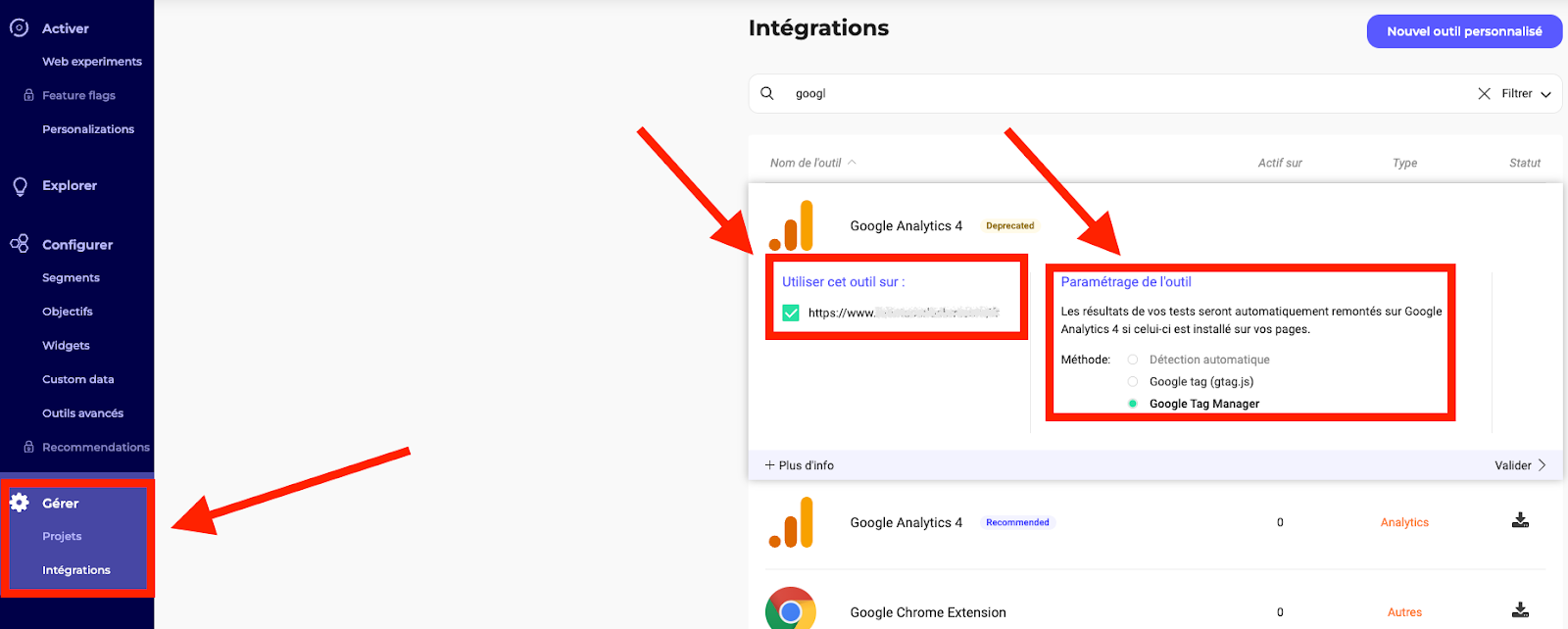
- テストを作成する際、「最終決定」、「トラッキングと目標」、「その他のトラッキングツール」の順に進み、GA4にチェックを入れると、このキャンペーンのA/Bテストイベントが アナリティクスツールに送信さ れるようになります(キャンペーンごとにパラメータを設定する必要があります)。
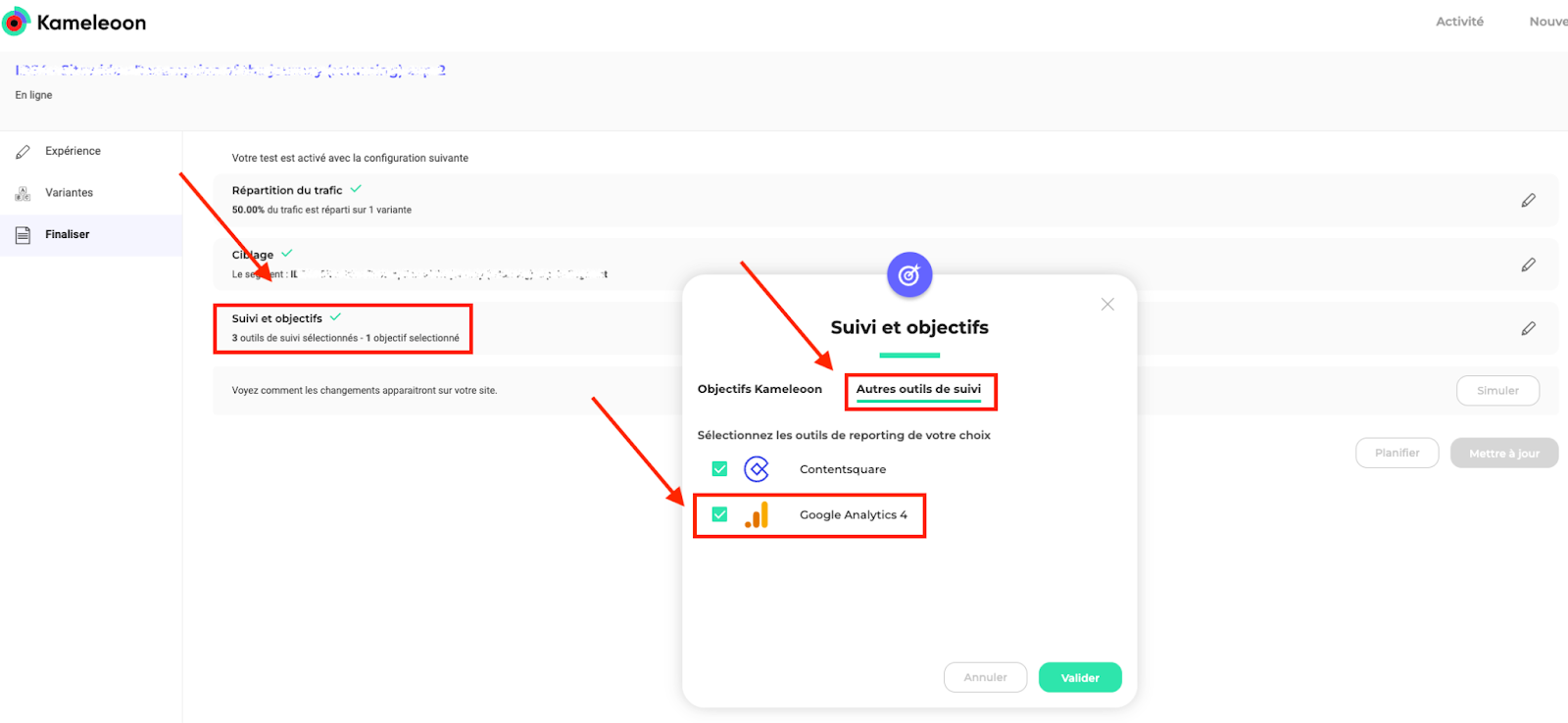
- テストを実行します。Google Analyticsは、あなたが開始し、設定したすべてのテストのイベントを自動的に作成します。
カメレオンとGA4間の接続が設定できたら、データがGA4に戻ることを確認できます。
データが実際に分析ツールに入力されていることを確認する。
レポートで、イベントが正しく設定されていることを確認してください。
この例では、kameleoonとGA4のデータを使用しています。 他のA/Bテストツールを使用している場合は、分析ツールとの統合時に設定したイベント名を使用する必要があります。
- GA4インターフェースにログオンしてください: https://analytics.google.com/analytics/web.
- レポート]タブに移動し、すべての分析結果を見つけます。
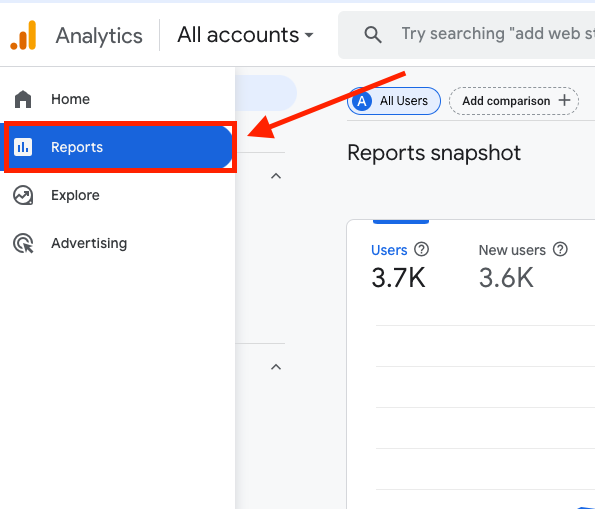
- Engagement "ペインを クリックして開き、"Events "をクリックしてイベントのインターフェイスにアクセスします。
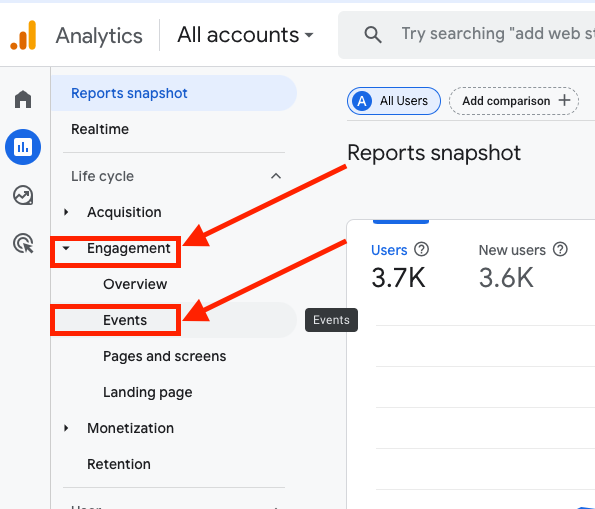
- インターフェイスに入ったら、アナリティクスとA/Bテストツールの統合時に確認した イベント名を検索バーに入力 します。
この例では、kameleoon_experiment イベントです。
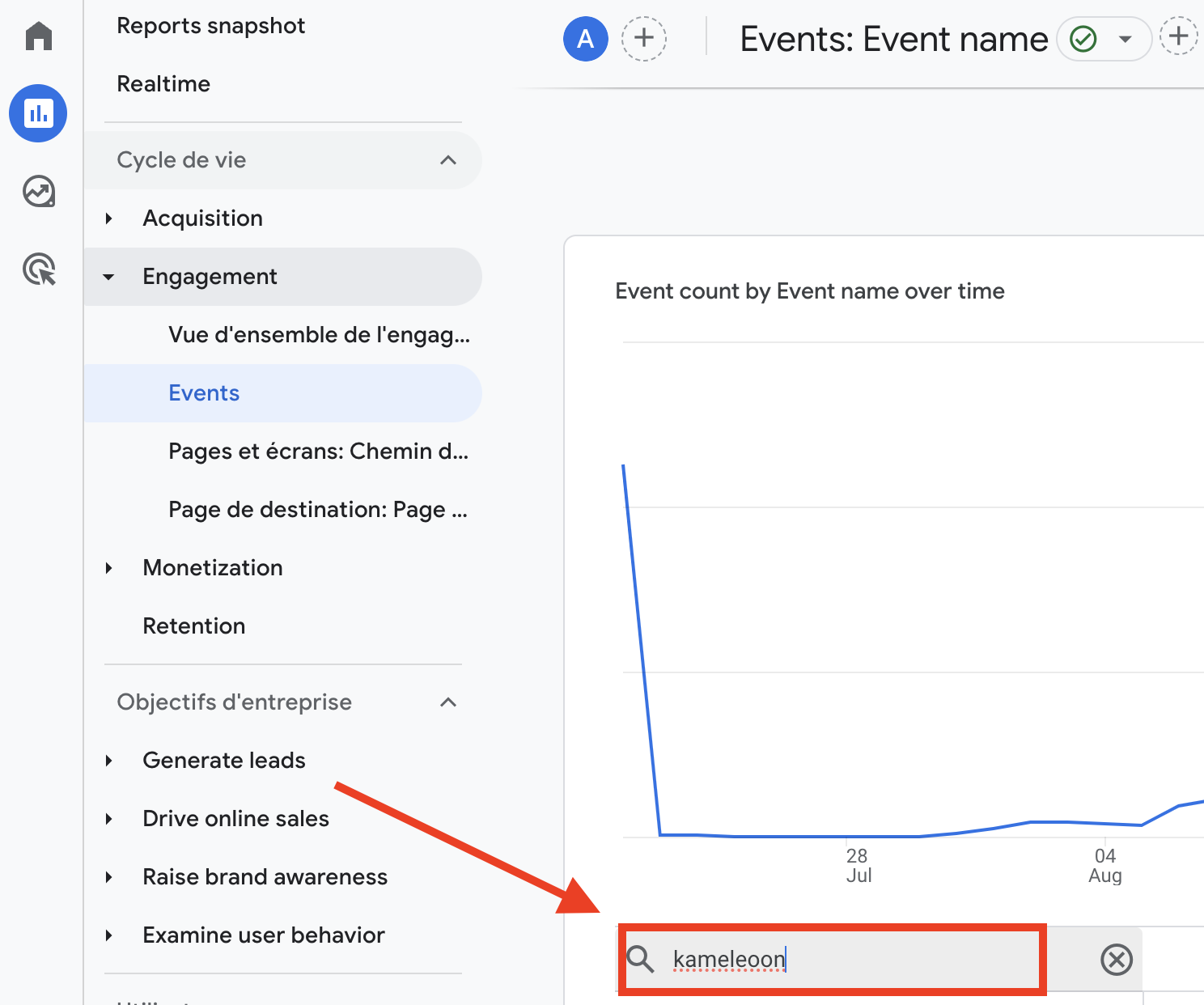
- enter "をクリックして、イベントの分析に進みます。

この例では、 A/Bテストに対応するデータがあることがわかります。 結果がない場合は、設定したイベントであることを確認するか、A/Bテストツールの設定を確認してください。
分析ツールにA/Bテストのデータが入ったので、ツールをBigQueryに接続します。
分析ツールをBigQueryに接続する手順
アナリティクスツールからデータをエクスポートするには、まず、抽出されたデータを受け取るためにBigQueryを設定する必要があります。 そのためには、Googleクラウドプラットフォームを設定する必要があります。
Google Cloud Platformとは?
Google Cloud Platform(GCP)は、BigQueryを含むクラウドコンピューティングサービス群です。 BigQueryを使用するには、GCPアカウントが必要です。
GCPの詳細については、Google Cloud Platformのプレゼンテーションをご覧ください。
以下は、セットアップするすべてのコンフィギュレーションである:
- GCPアカウントを作成する
- プロジェクトを作成する
- 支払い口座の設定
- BigQueryの設定
- データ転送APIの設定
GCPアカウントの作成
- Google Cloud Platformのアカウントを作成する:
これを行うには、https://cloud.google.com/?hl=fr、"Start now "をクリックする。
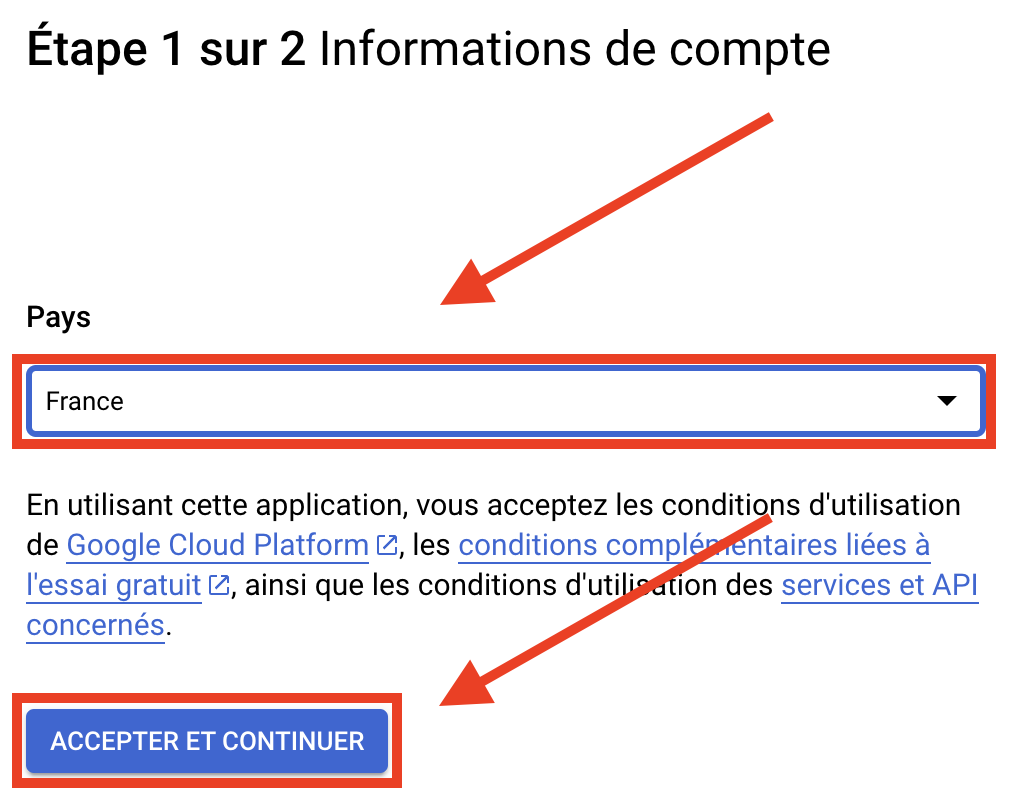
国を選択し、承諾する。
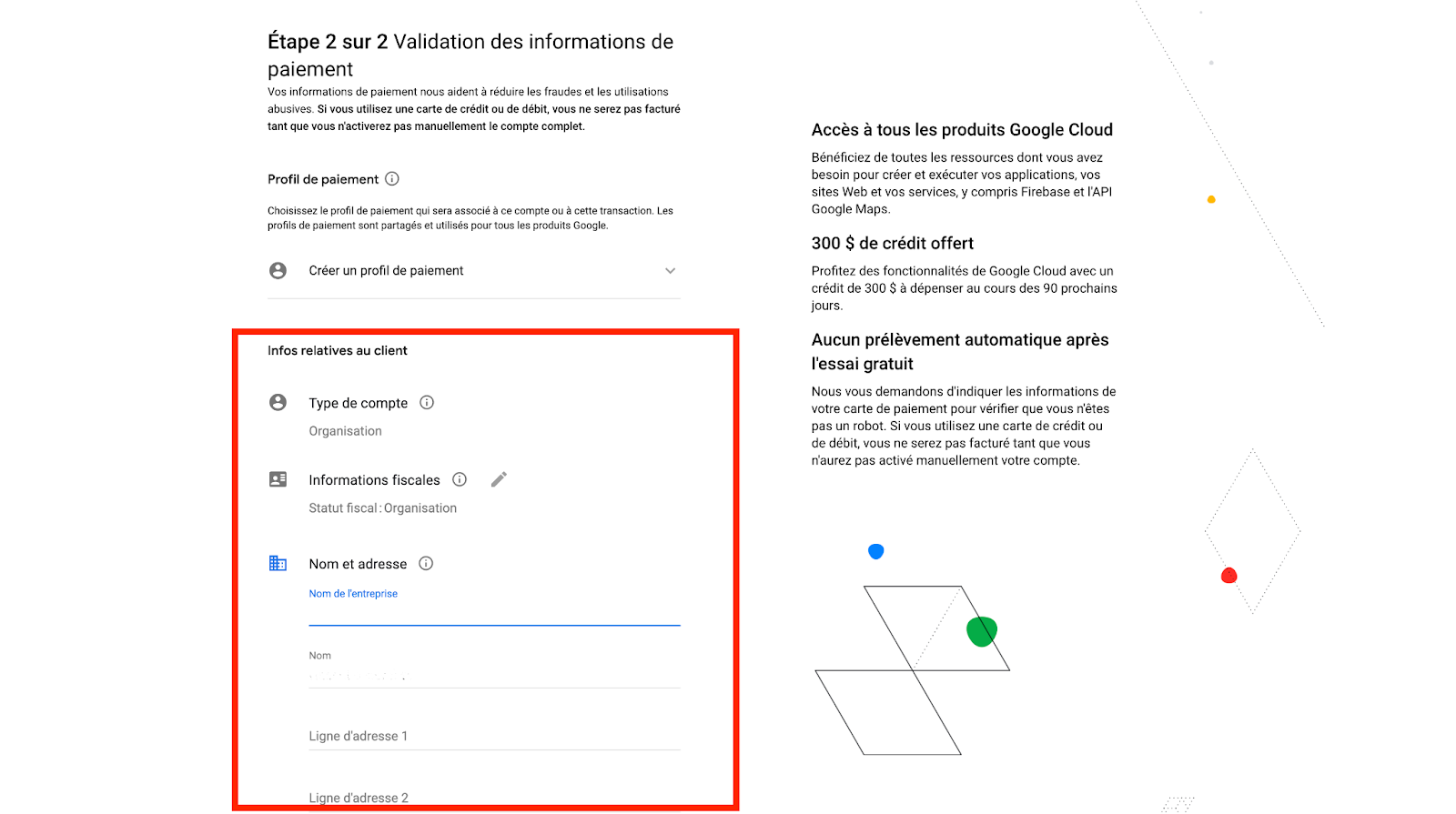
お支払いの詳細を入力してください。
無料トライアルを開始」をクリック。

- 新しいプロジェクトを作成する:
プロジェクトとは何か?
GCPプロジェクトは、データとアプリケーションが一元化された単一のワークスペースであり、組織全体のコラボレーションとプロジェクト固有の課金を促進します。
つまり、請求書の発行や整理を簡単にするために、1つのプロジェクトを作成したり、すべてのデータをその中に統合したりすることができる。
GCPのプロジェクトの詳細については、プロジェクトの概要をご覧ください。
まだプロジェクトを作成していない場合は、GCPインターフェースhttps://co nsole.cloud.google.com/welcome、"New project "をクリックして ください。
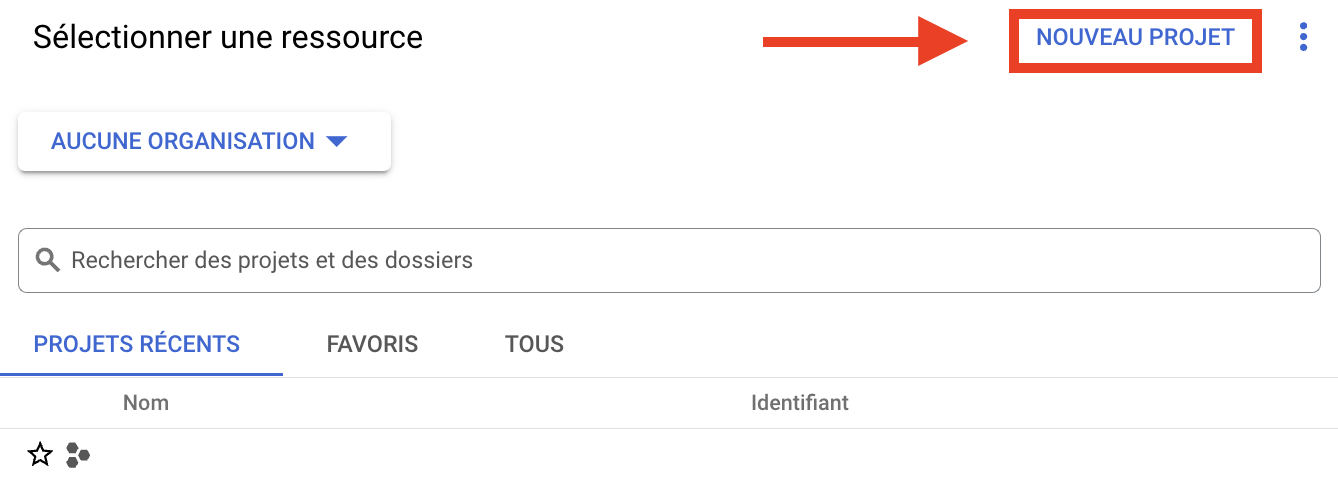
- プロジェクト名を記入してください。会社名のような大まかな名前でもかまいません。
- GCPアカウント作成時に設定した組織を選択します。
- プロジェクトを統合するフォルダに対応するゾーンを選択します。
- そして「Create」を押す。
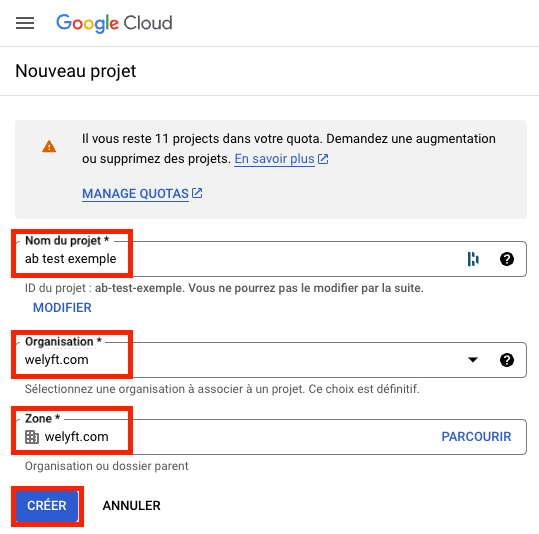
- プロジェクトの請求アカウント
課金口座とは何ですか?
Google Cloud Platform (GCP)の課金アカウントは、課金を管理するエンティティであり、プロジェクトにリンクすることで、関連するすべてのコストを一元化して管理することができます。
課金アカウントの詳細:課金アカウントを管理する。
BigQueryのData Transfer APIを有効化するには、課金アカウントが必要です (Data Transfer APIとは何かは後で説明します)。
課金アカウントの作成方法を教えてください。
すでに作成済みの場合は、こちらをご覧ください。(リンク先:課金アカウントをプロジェクトにリンクする方法)。
GCPアカウント作成時に請求先アカウントを作成していない場合、請求先アカウントを作成する必要があります:
GCPインターフェースにアクセスし、"billing account in search bar "と入力して、"Billing Account "をクリックする。
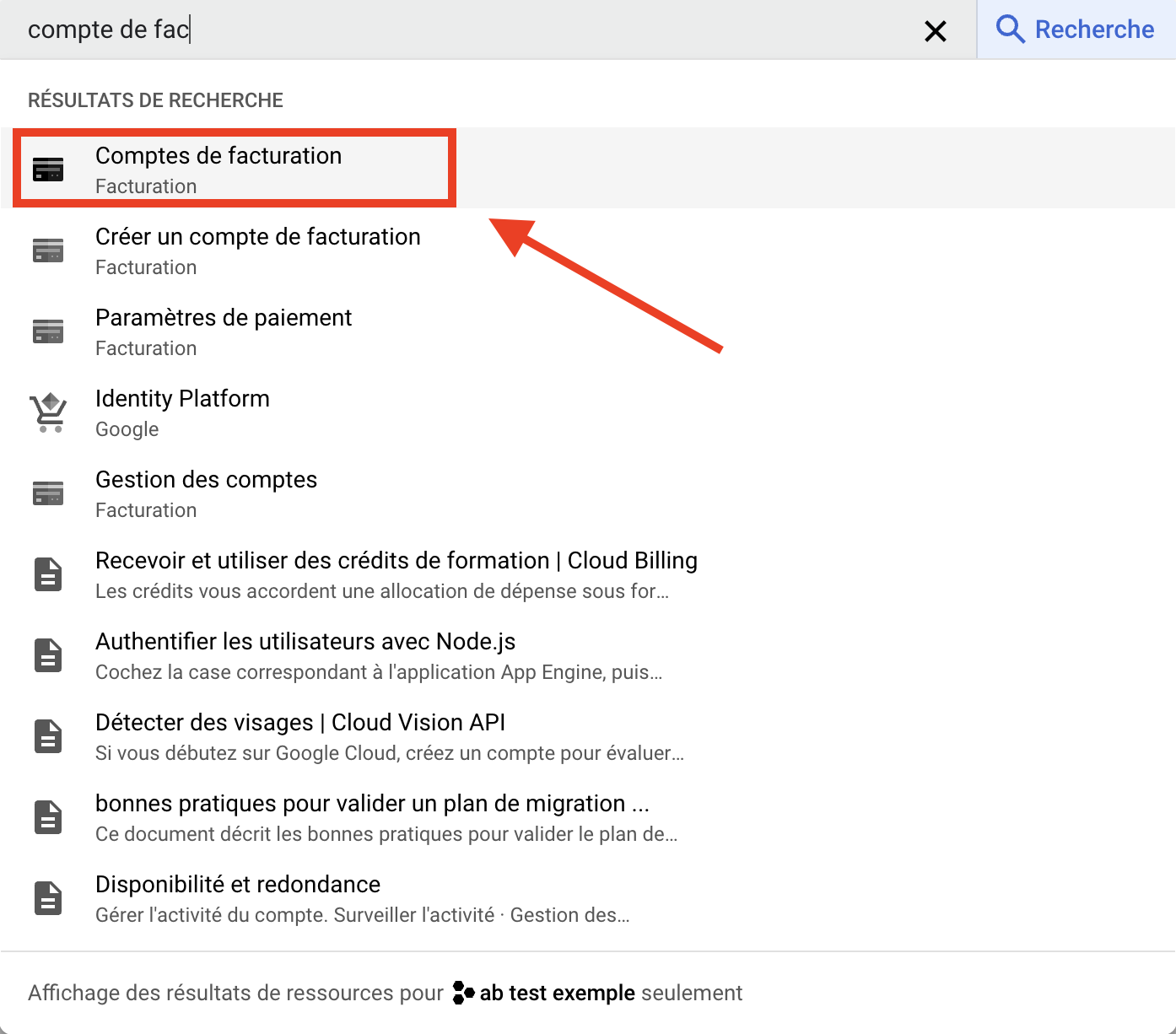
GCPは「このプロジェクトには課金アカウントが含まれていません」と言うので、「課金アカウントを管理」をクリックします。
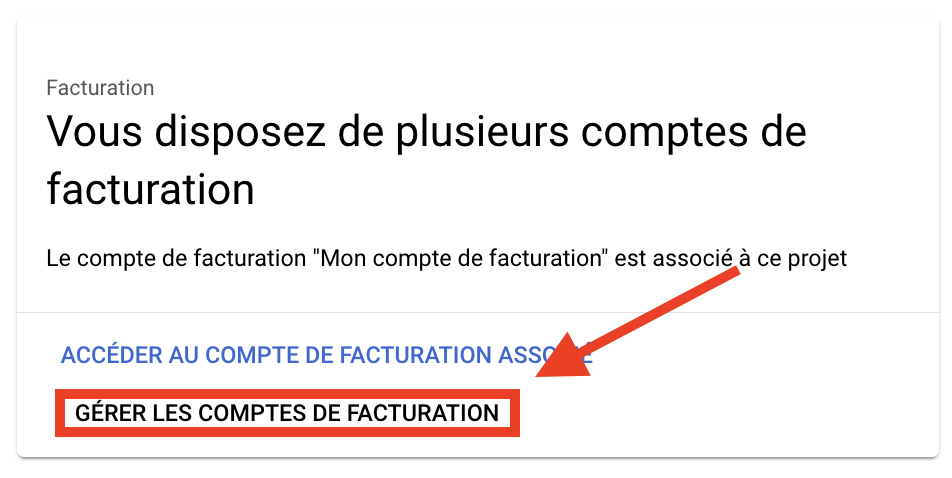
課金アカウントの追加」をクリックします。

国を選択してください。

課金口座の作成は以下のような構造になっている:
- 口座の種類
- 税務情報
- 氏名および住所
- 主な連絡先
- 支払い処理
- 支払方法
記入すべき情報を順を追って見ていきましょう。
アカウントの種類は 、あなたが個人か会社かを示すために使用されます。
課税状況は、前回の選択に従って自動的に入力されます。納税情報については、納税状況を入力するだけで、あとは任意です。
名前と住所は、組織の場合は:
- 会社名
- 法的責任者の氏名。
- 登録事務所の住所、郵便番号、町名。
メインの連絡先 "に連絡先の名前とメールアドレスを追加する。
支払い処理に関しては、90日間の無料アカウントが提供されるので、心配する必要はない。GCPトライアル版についての詳細は、https://cloud.google.com/free?hl=fr。

その後、お支払いの詳細を入力してください。
課金アカウントをプロジェクトにリンクする方法は?
請求アカウントの管理」に戻る。
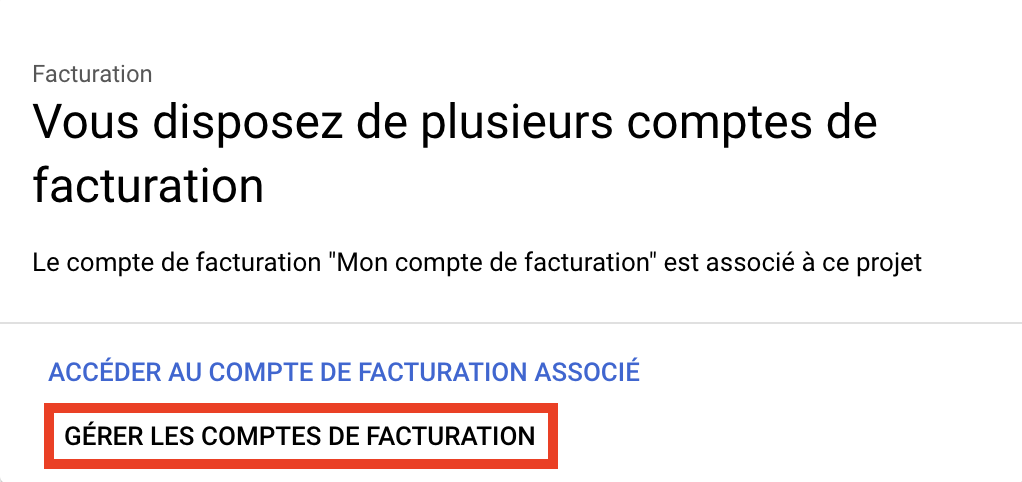
組織を選択し、課金アカウントを選択してプロジェクトに関連付けます。

プロジェクトに関連付けられた課金アカウントを取得したら、BigQuery APIを有効にしてBigQueryにアクセスし、次にData Transfer APIにアクセスします。
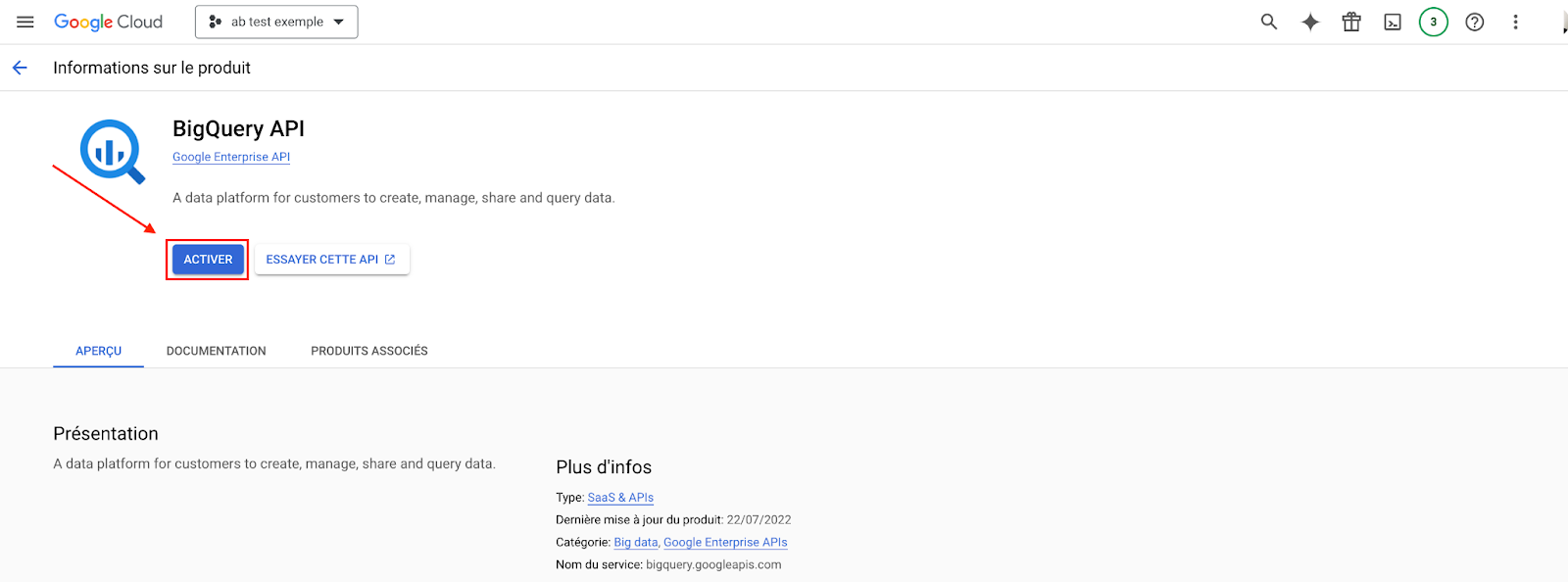
BigQuery APIの有効化
- 有効化するBigQuery APIAPIを有効にすると、ほとんど即座に有効になります。
これにより、BigQueryツールにアクセスできるようになり、データを受け取ることができる。
- BigQueryのデータ転送APIを有効にします:
BigQuery Data Transfer APIとは何ですか?
これによって、次のことが可能になる:
- データ転送の自動化(クエリ経由)。
- 移籍モニタリングの管理
- エラー管理。
- データセットの自動更新
私たちの場合、APIを使用することで、A/Bテストデータを集計するための自動クエリーを作成し、Looker Studio用のテーブルを作成することができます。
BigQueryのデータ転送APIを有効化するには、以下にアクセスして ください。 APIデータ転送 有効化には数時間かかる場合があります。
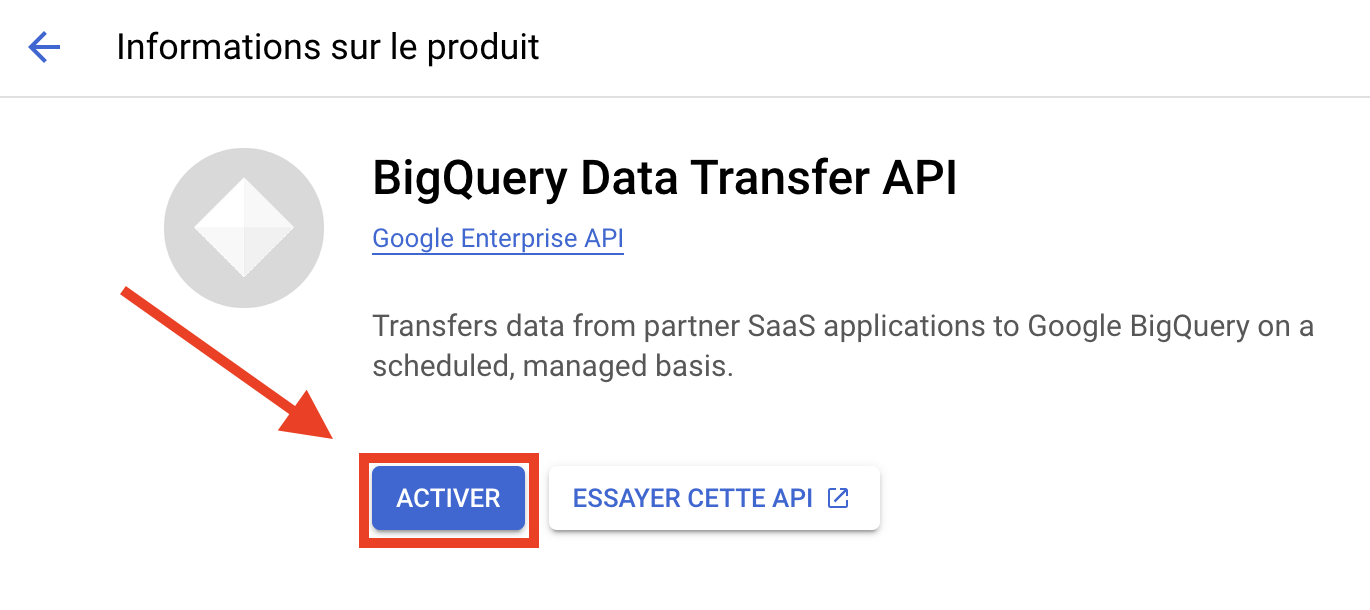
APIが有効化されると、データを処理するためのすべての準備が整います。次のステップは、GA4データをBigQueryにエクスポートすることです。
アナリティクスツールにアクセスし、BigQueryとの統合を有効にします。
GA4にて
- Google Analytics 4のアカウントにログインします: https://analytics.google.com/analytics/web.
- 管理設定に移動し、"BigQuery Links "オプションを見つけます。
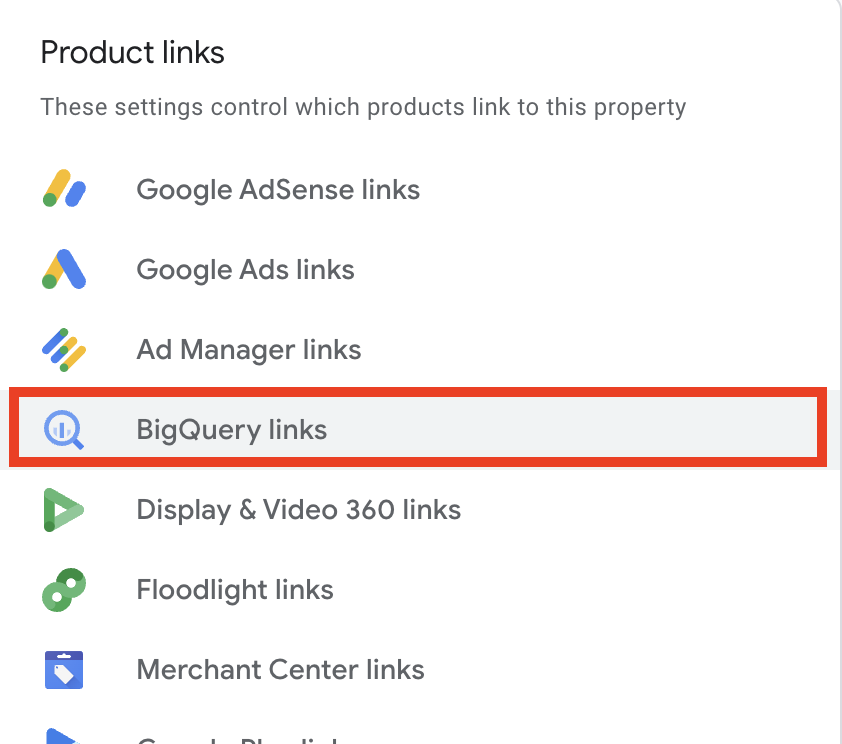
- リンク」を クリックして、BigQueryコネクタの設定を開きます。

- プロジェクトの選択」をクリックする。
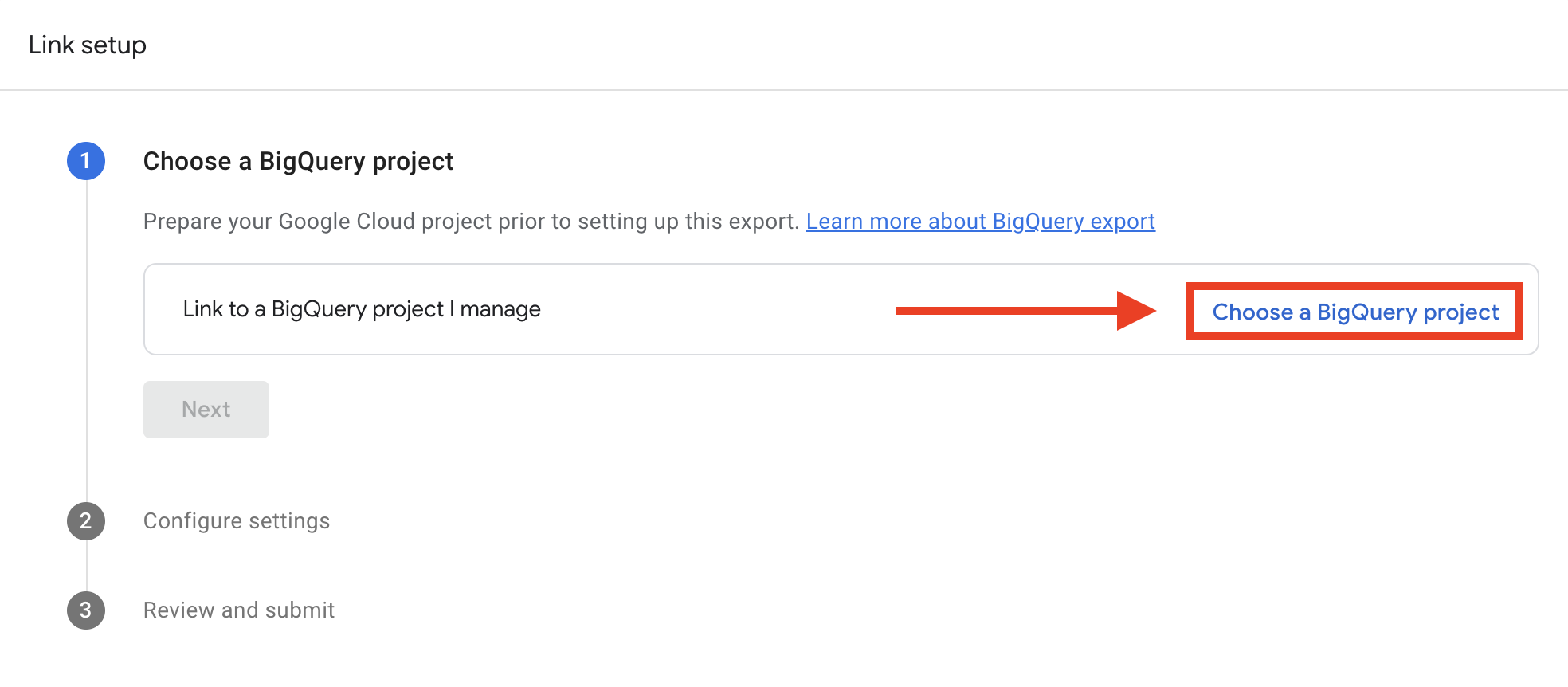
- 先ほどGCPで作成したプロジェクトを選択 し、 「Confirm」をクリックします。

- データの保存場所を選択します。 プロジェクトと同じ場所を選択しないと、データが受信されません。
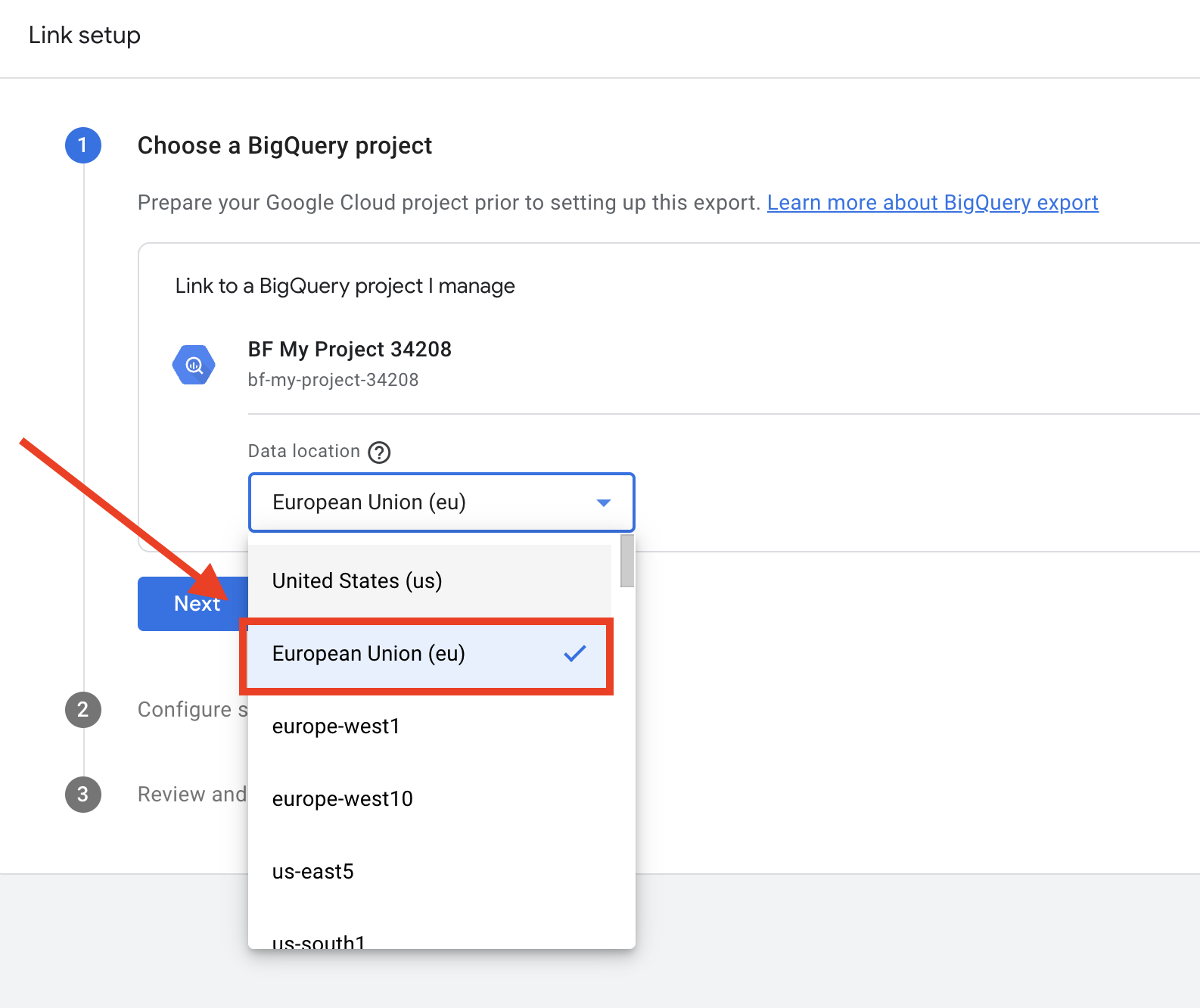
- エクスポートのタイプを選択して頻度を設定する。
GA4からBigQueryへのエクスポートには2種類あります:
- リアルタイム更新のためのストリーミングは、より高価なオプションである。
- 1 日1回のデータ転送のデイリーストリームとして。
詳しくは、輸出の頻度と価格に関する資料をご覧ください:
この例では、より一般的で、依頼しやすく、安価であることから、日次輸出を選択した。
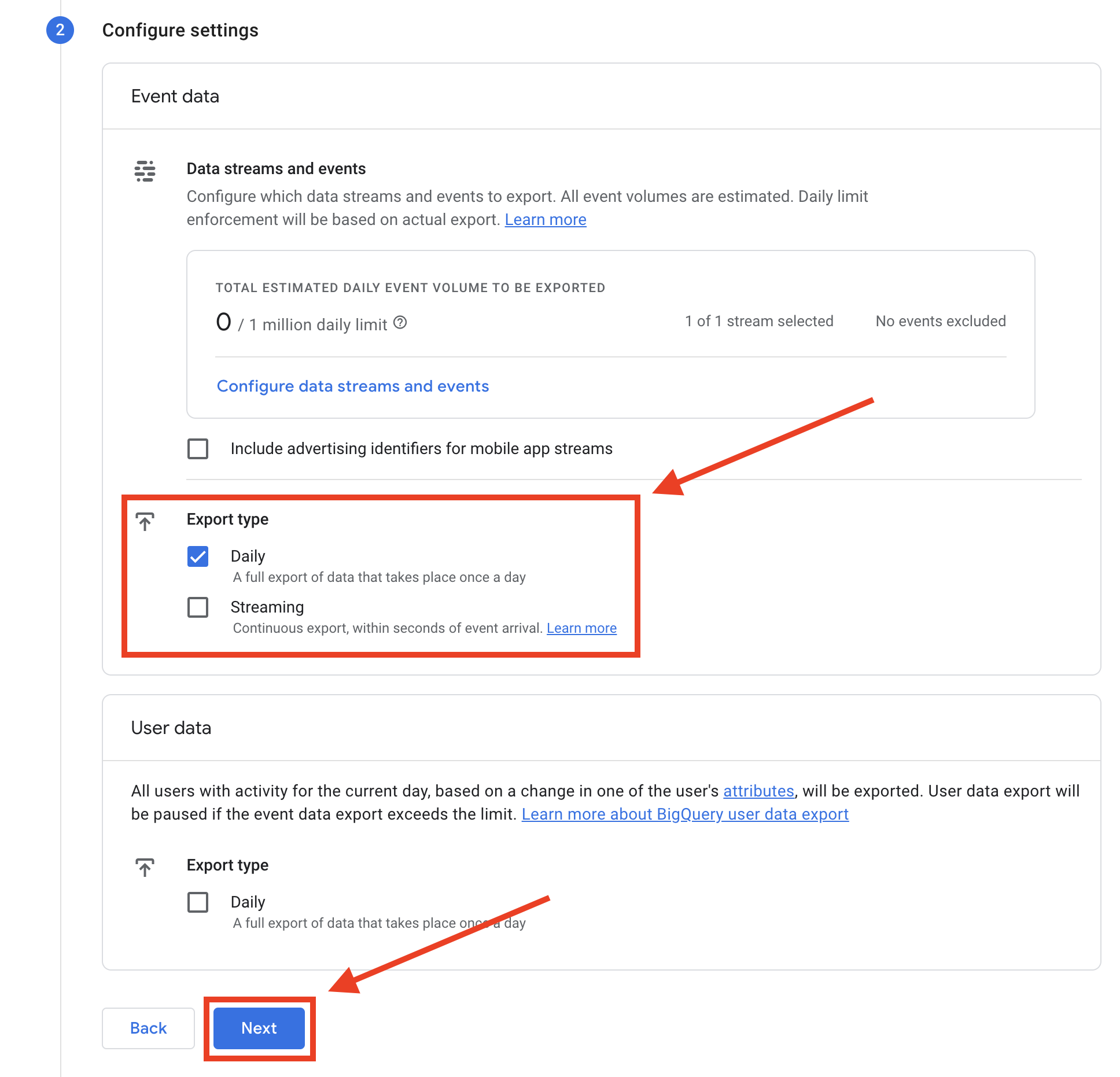
そして「次へ」をクリックする。
- BigQueryリンクを作成すると、この成功メッセージとBigQueryプロジェクト名が表示されます。
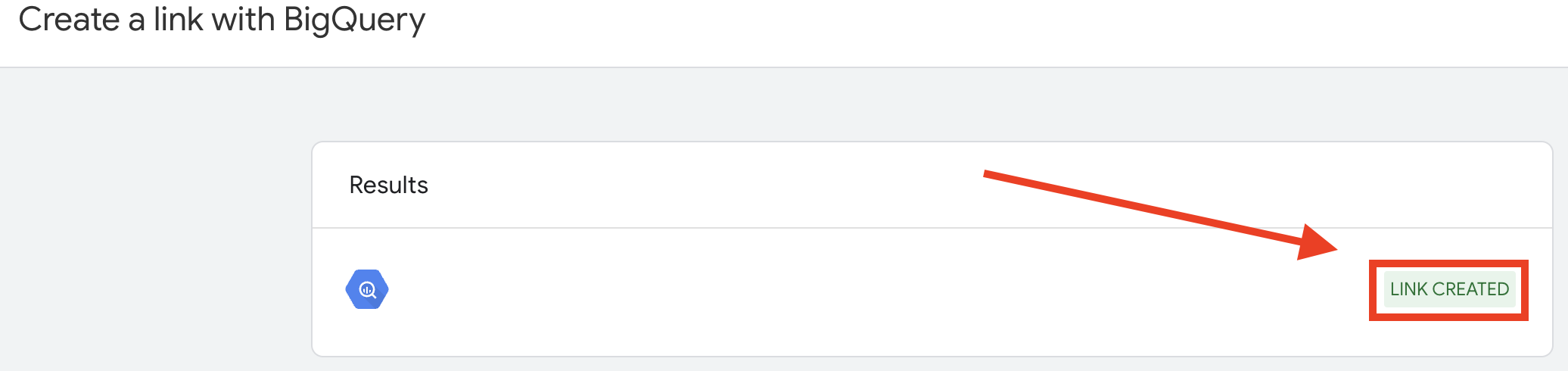
GA4とBigQueryのリンクを作成したら、BigQueryに戻ってデータを受け取ったことを確認します。
イベントデータがBigQueryに正しくエクスポートされているか確認する
- 日次輸出を選択した場合:翌朝まで待つ。
- ストリーミング・エクスポートを選択した場合:直接確認することができます。
GA4データがBigQueryに存在するかどうかを確認する。
- このサイトへ ビッグクエリ.
- 次にBigQuery Studioに アクセスします。
- エクスプローラーを表示すると、すべてのデータソースにアクセスできます。
- GA4データセットが存在し(GA4 BigQuery接続を作成した場合は自動的に追加されるはずです)、その名前が "analytics_"で始まっていることを確認します。
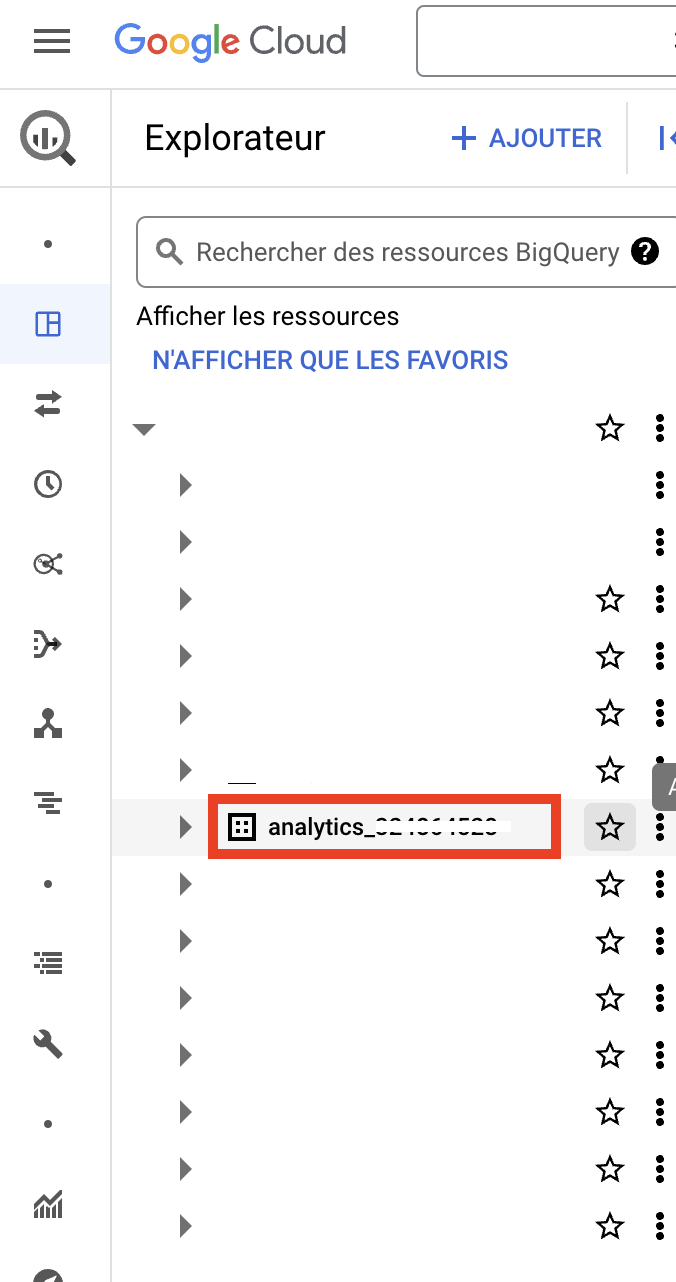
- チェックが完了したら、 矢印をクリックしてノードを展開すると、"events_"テーブルが表示される。

- これをクリックすると、すべてのテーブル・パラメーターが表示される。

- プレビュー」をクリックすると、すべてのデータのプレビューが表示され、GA4のデータがあることを確認 できます。
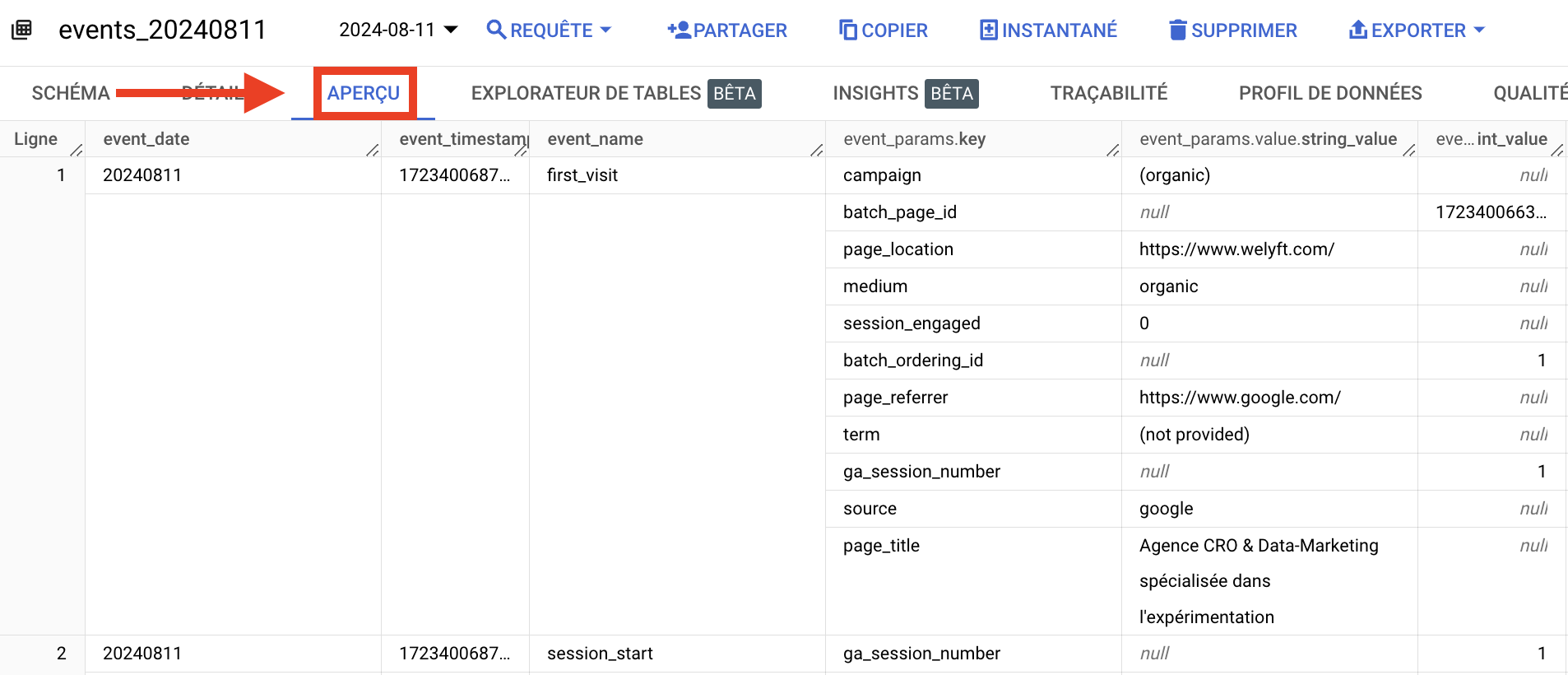
ちなみに、GA4は イベントベースの構造を採用しており、各ユーザーとのやりとりは、コンテキスト詳細を提供する追加パラメータを持つイベントとして記録される。
GA4のデータは以下のような構造になっていることがわかる:
- evenent_name:イベント名
- event_params.key: イベント・パラメーターの名前
- event_params.value.string_value:文字列形式のパラメータ値(文字列)
- event_params.value.int_value: int形式のパラメータ値(数値)
event_params.keyカラムはイベント・パラメータに対応し、分析に必要なディメンションを定義するために使用されます。
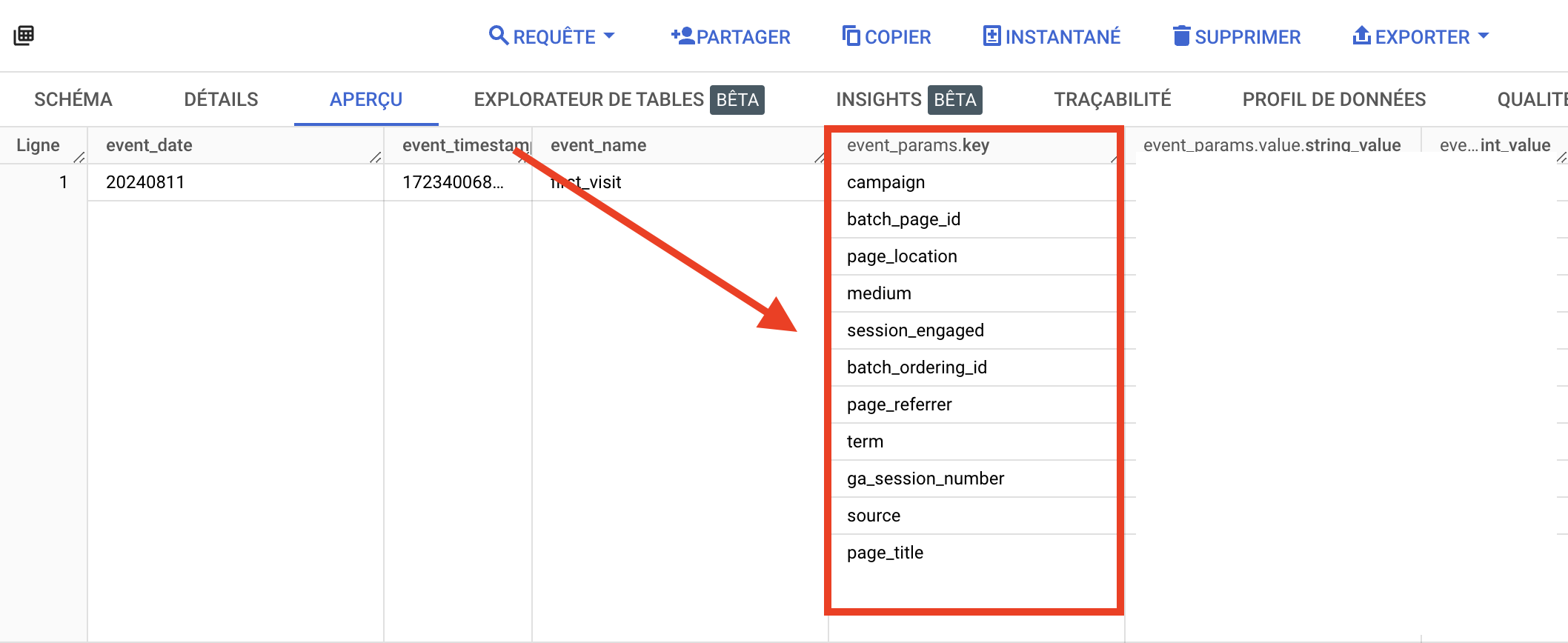
event_params_valueカラムは、各種パラメータの値である。
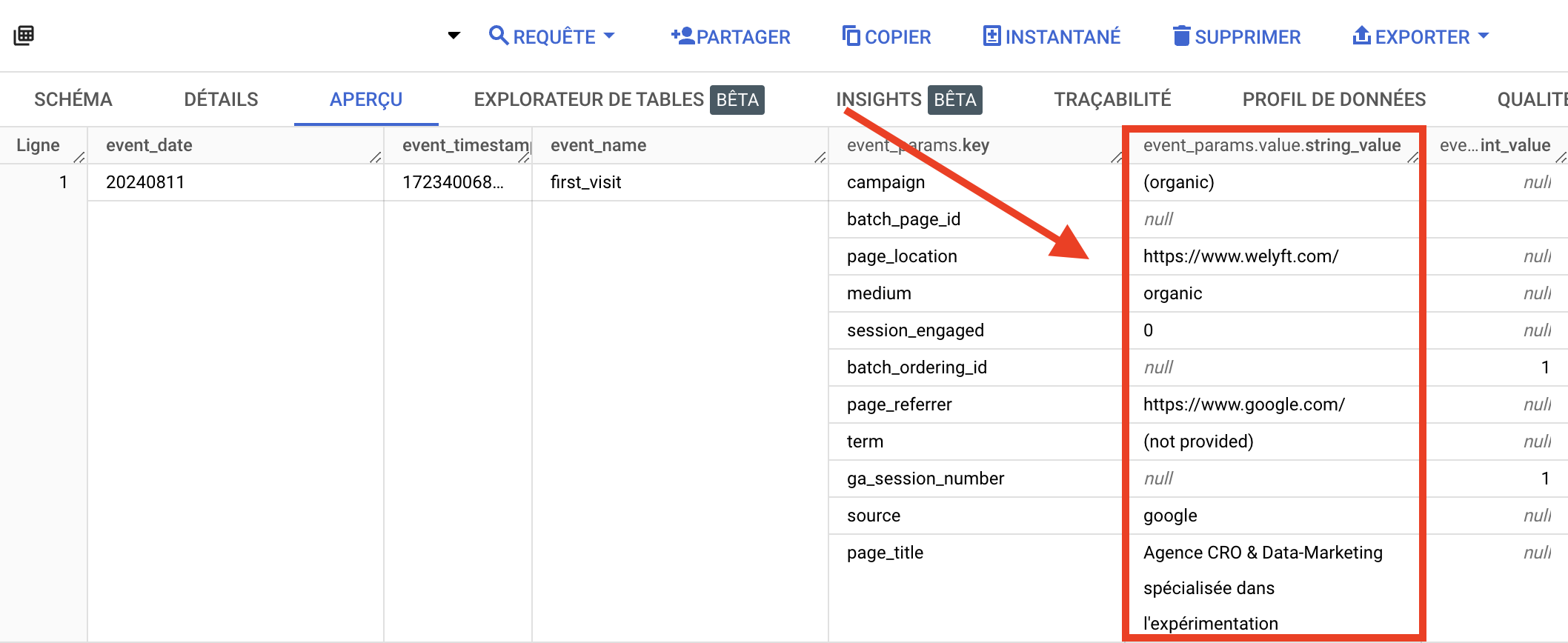
BigQueryにGA4データが入ったので、このGA4データセットからA/Bテストデータを加工していきます。
BigQueryでA/Bテストデータを活用する
BigQueryのA/Bテストイベントを理解する
この例では、KameleoonのA/Bテストデータを使用します。
データを処理する前に、GA4エクスポートのA/Bテストイベントで使用できるものを分析する必要があります。
フィルタを使用してA/BテストのイベントをターゲットにするSQLクエリを作成します。
- BigQueryにアクセスし、"SQL REQUEST "をクリックする。
空白のウィンドウが表示され、そこにSQLクエリを書いてテストすることができます。
AB Testイベントで何が悪用されるかを正確に分析するために、クエリーでフィルターを使用してこれらのイベントをターゲットにすることができます。
- A/Bテストのイベントをターゲットにするには、以下のクエリーを使用します:
SELECT * FROM `project_name.analytics_XXXXXX.events_XXXX` where event_name in("your_event_name") LIMIT 10
- 実行」をクリックする。

- 実行後は、ABテストイベントを分析することができます。
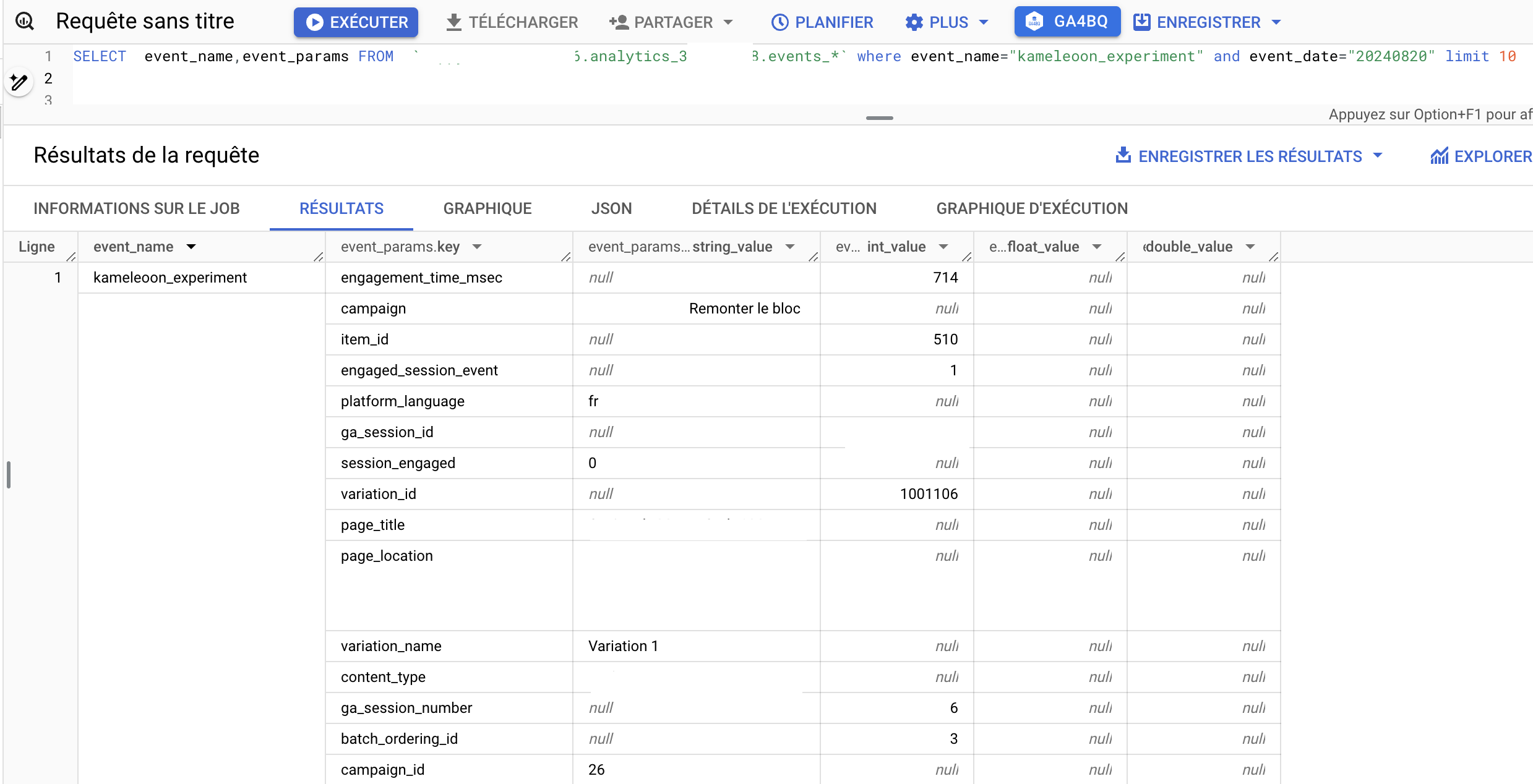
これにより、 A/Bテスト分析に必要なすべての ディメンションと指標を定義することができます。
分析の次元と測定基準を定義する
分析に必要なディメンションとメトリクスの特定と分類から始めましょう: A/Bテストのパフォーマンスを反映する主要なディメンションとメトリクスの作成(KPIのカスタマイズもあります)。
分類の例:
- G4 ネイティブディメンジョン: experiment_name、variation_name、campaign_id、device_type。
- コンバージョン率、セッション数、ページビュー、平均セッション時間。
- BigQueryの メトリクスの カスタマイズアップリフト、ダウンリフト。
ディメンジョンとメトリクスが定義されたら、SQL クエリを設定できます。
BigQueryでデータを集約するためのSQLクエリを準備する
分析に必要なものが分かったら、ニーズに合わせたSQLクエリを作成する必要があります。 クエリの生成にはAIを使用できます。
以下は、上記のディメンジョンとメトリクスを取得するためのクエリの例です:
WITH experiment_events AS (SELECT user_pseudo_id,event_timestamp,event_name,(SELECT value.string_value FROM UNNEST(event_params) WHERE KEY='campaign') AS campaign,(SELECT value.string_value FROM UNNEST(event_params) WHERE KEY='variation_name') AS variation_name,(SELECT value.int_value FROM UNNEST(event_params) WHERE KEY='campaign_id') AS campaign_id,device.category as device_type FROM `project_name.data_set.events_*` WHERE event_name IN ('kameleoon_experiment','conversion','session_start','page_view')), session_metrics AS (SELECT user_po_id、AVG(event_timestamp) OVER (PARTITION BY user_pseudo_id) - MIN(event_timestamp) OVER (PARTITION BY user_pseudo_id) AS session_duration FROM experiment_events WHERE event_name='session_start') SELECT campaign,variation_name,campaign_id,device_type,SAFE_DIVIDE(COUNTIF(event_name='conversion'),COUNTIF(event_name='session_start')) AS conversion_rate,COUNTIF(event_name='session_start'))AS conversion_rate,COUNTIF(event_name='session_start') AS sessions,AVG(session_duration) AS session_average_time,SAFE_DIVIDE(COUNTIF(event_name='conversion'),COUNTIF(event_name='session_start'))-(SELECT SAFE_DIVIDE(COUNTIF(event_name='conversion'),COUNTIF(event_name='session_start'))。FROM experiment_events WHERE variation_name='control') AS uplift,(SELECT SAFE_DIVIDE(COUNTIF(event_name='conversion'),COUNTIF(event_name='session_start'))FROM experiment_events WHERE variation_name='control')-SAFE_DIVIDE(COUNTIF(event_name='conversion'),COUNTIF(event_name='session_start')))。AS downlift FROM experiment_events JOIN session_metrics USING (user_pseudo_id) GROUP BY campaign,variation_name,campaign_id,device_type ORDER BY conversion_rate DESC limit 10
しかし、 、このクエリーから ヒントを得て、独自のクエリーを作成することができる。
その後、先ほどのクエリ実行と同じ プロセスに従って、BigQuery Studio で クエリを実行し、 結果を確認 します。

クエリーの結果が得られたら、自動的にトリガーされるプログラムされたクエリーを作成することができます。
プログラムされたクエリを作成する
自動クエリーを使用してテーブルを作成し、Looker Studioが接続できるようになります。
BigQuery Studioでクエリの結果が良好な場合は、次の手順を実行できます:
- スケジュール」をクリック。

右側にウインドウが開き、そこでリクエストを設定 することができます。
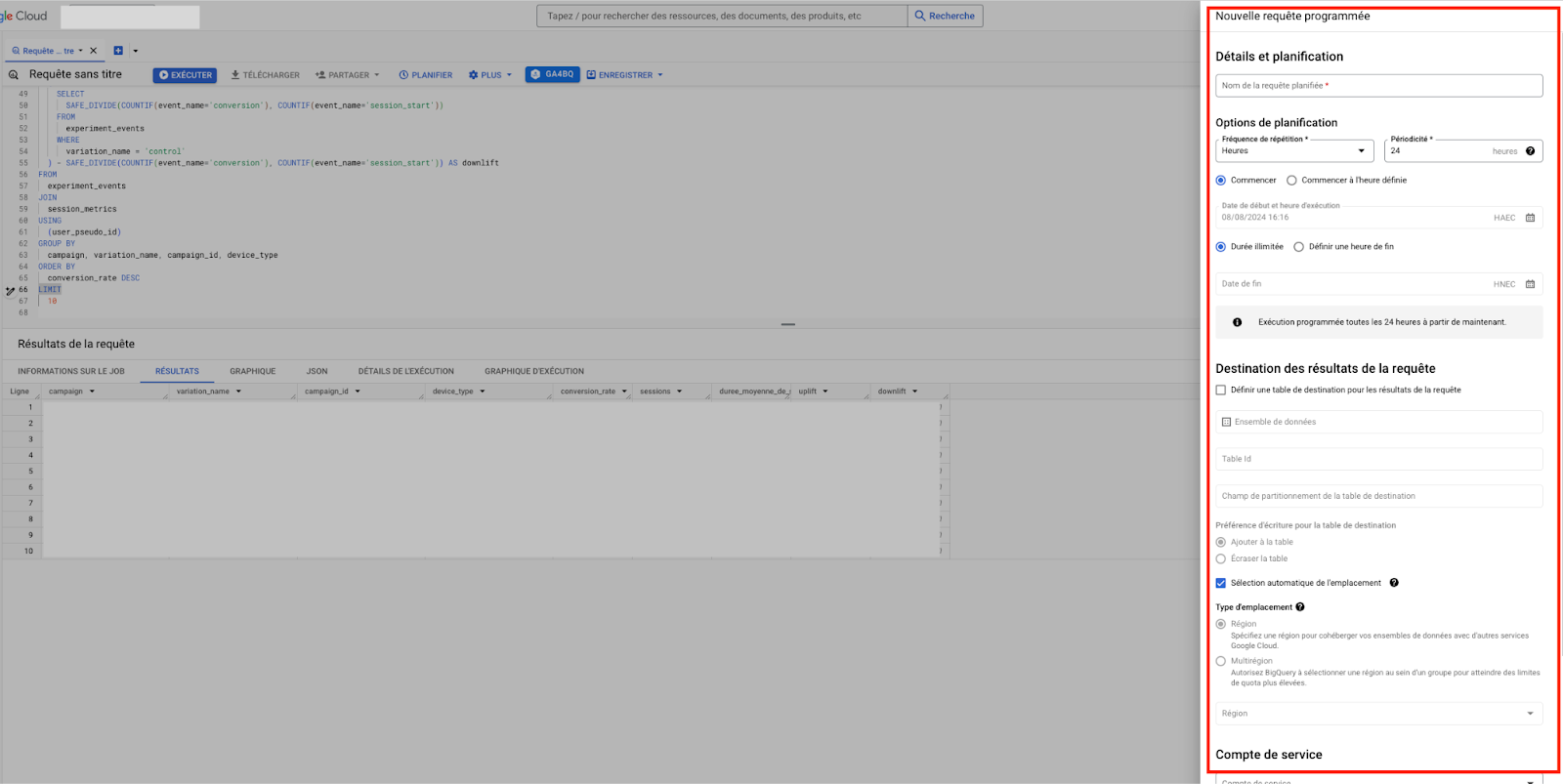
- スケジュールされたリクエストを設定する :
- リクエストの名前:プロジェクト名やサイト名、テストの種類を "ab test "とすることができます。
- 繰り返しの頻度 :あなたのニーズに最も適した頻度を選択することができます。 私たちは、週ごとの概要を提供し、GA4の毎日のエクスポートに適応するために、日別の頻度を選択します。
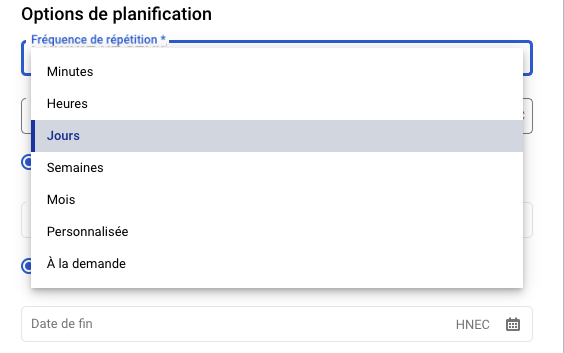
- 繰り返し頻度の時間:時間はUTCで、データを受信する前にリクエストがトリガーされないように、GA4データの受信より遅い時間を選択する。

- 開始時間と終了時間 :もし何も触らなければ、リクエストは私たちのプログラミングに従って、次に実行されるときに初めてトリガーされ、無期限に同じ頻度で実行される。
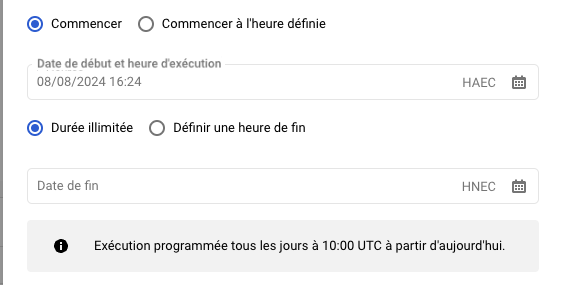
- リクエストの宛先を定義する。
あなたができる:
- 専用データセットの作成
- 既存のデータセットを選択する(GA4接続で作成したanalytics_XXXXXXデータセットなど)

両方の可能性について、どのように進めていけばいいのかを見ていくことにしよう。
- 専用データセットの作成: 専用データセットを作成 したい条件で、「CREATE A DATA SET」をクリックする。

- ウィンドウが開くので、データセットに名前を付けます (例:A/B Test)。次に地域を選択し(アナリティクスのデータセットと同じ地域を選択する必要があります。

- データセットが作成されたら、データセットを選択し、移動先のテーブルに名前を付けます(多くの場合、簡単にするために、スケジュールされたクエリとテーブル名を同じ名前にします)。

- 執筆の好み:
- テーブルに追加: テーブルの後に行を追加し、重複を避けるためにSQLクエリを適応させる。
- テーブルを上書きする: クエリを実行するたびにテーブルを新しいクエリ結果に置き換えます。

- 自動ロケーション選択 "にチェックを入れると、自動的に地域を選択することができます。
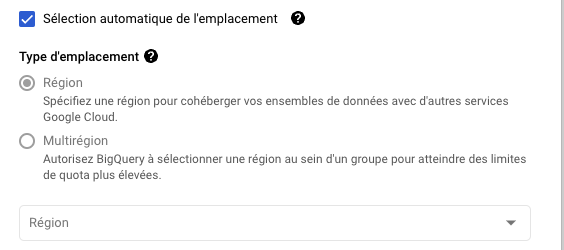
手動で選択する場合は、アナリティクスのデータセットと一致する必要があります。
- プログラムされたリクエストを保存し、左側のメニューから"Programmed requests "を選択することで、リクエストがプログラムされたことを確認することができます。
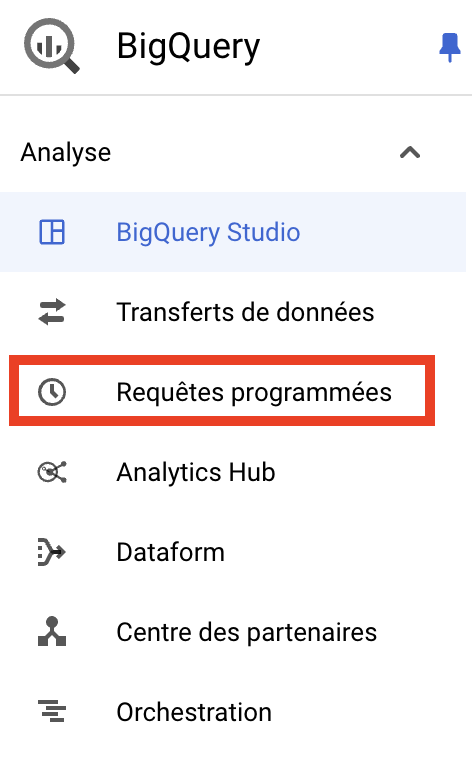
これはプログラム・クエリーのインターフェイスである:

以下の情報をご覧ください:
- クエリー名
- ソース:常にスケジュールされたクエリー
- スケジューリング:あなたのスケジューリング設定に対応します。
- 地域:プログラムリクエストを設定した地域
- 保存先データセット:クエリーの結果が保存される保存先です。
- 次のラン
- アクション削除または無効化することができます。
プログラミングに問題がないことを確認するためにリクエストをテストしたい場合は、手動で実行することができます。
これを行うには、あなたのリクエストをクリックして、スケジュールされたリクエストの詳細を表示し、 [Schedule filling]をクリックします。

Backをクリックすると、リクエストがこのシンボルで処理されていることがわかります。

実行に問題がなければ、検証マークが表示されます。

このような場合は、リクエストの詳細で エラーの詳細と解決方法を確認してください。これには多くの理由が考えられます。以下は、問題が発生した場合のドキュメントです : リクエストの実行に関する問題.
リクエストをプログラムしたら、ルッカースタジオとの接続は完了です。
Looker StudioでA/Bテストのモニタリングダッシュボードを作成する
Looker StudioとBigQueryの接続方法は?
Looker StudioにはネイティブのBigQueryコネクタがあり、BigQueryテーブルのデータを直接使用することができます。
- このページのトップへ ルッカースタジオ.
- アカウントをお持ちでない場合は、アカウントを作成してください。
- BigQueryテーブルをデータソースとして定義します。次に create をクリックし、次に data source をクリックします。
- BigQueryコネクタを選択します。
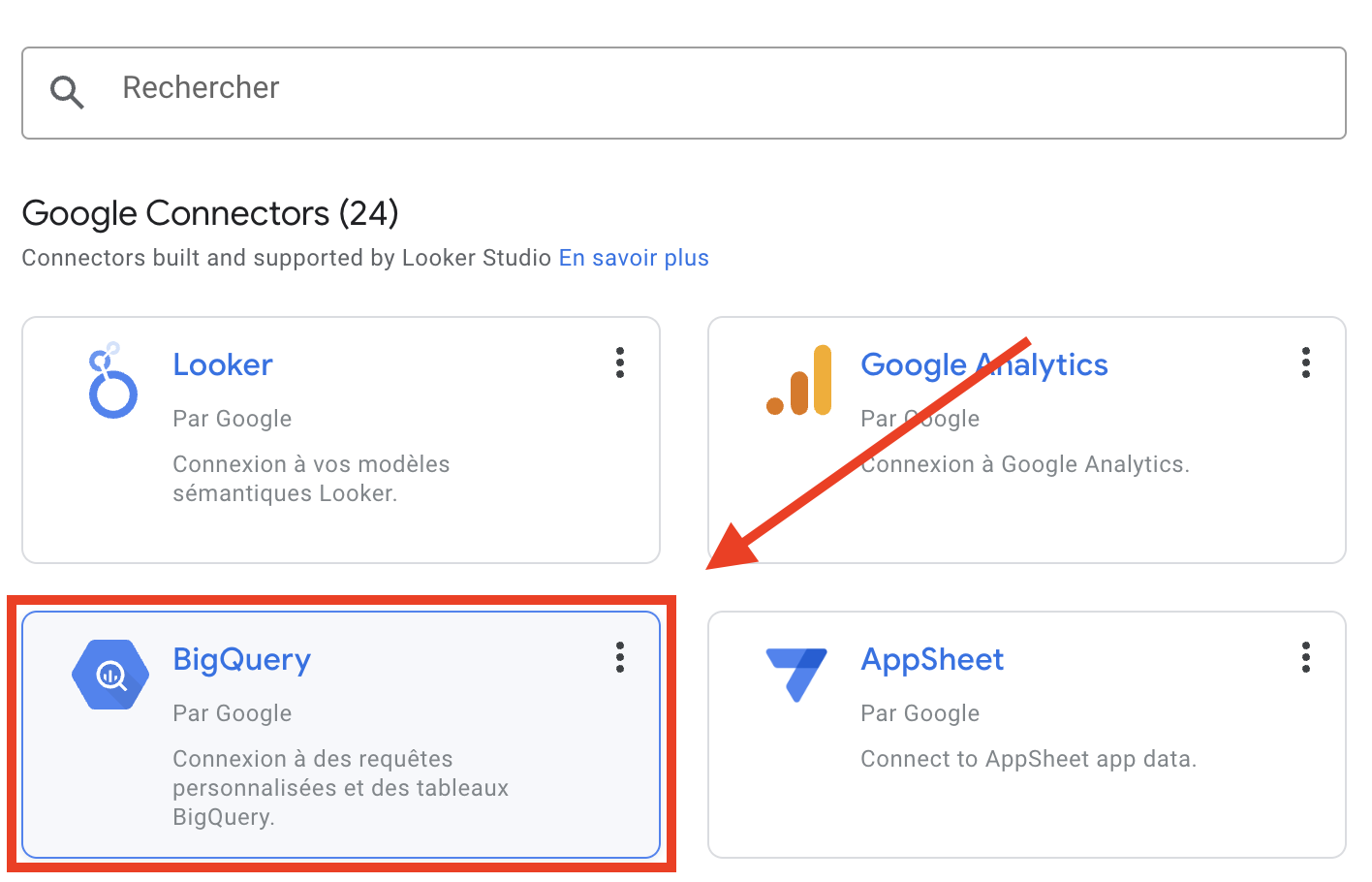
- 対応するテーブルを選択します:プロジェクトを選択し、データセットを選択し、プログラムしたクエリ先のテーブルに対応するテーブルを選択し、関連付けをクリックします。

- データソースに名前を付けます。 例えば 、"A/B Test - BigQuery"。
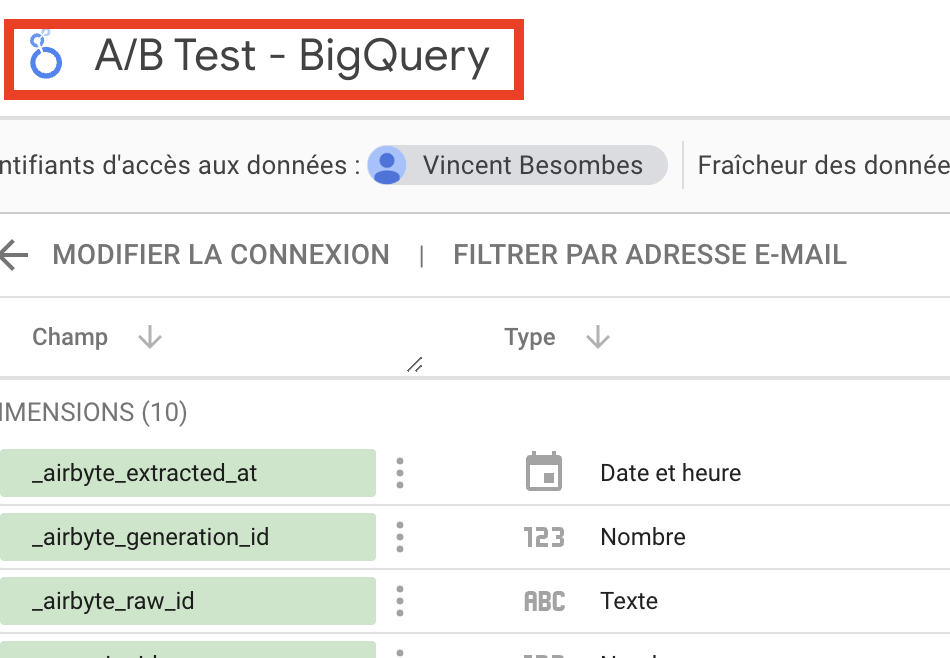
データソースがLooker Studioに統合されたので、ダッシュボードの作成を開始できます。
ダッシュボードの作成
Looker Studioでテーブルに接続したら、利用可能なディメンションとメトリクスを使用してダッシュボードを作成し、A/Bテストのパフォーマンスを簡単に表示、分析できます。
- ダッシュボードとなるレポートを Looker Studio で作成 します。
レポートを作成する際、Looker Studio は自動的にデータソースの追加を要求します。
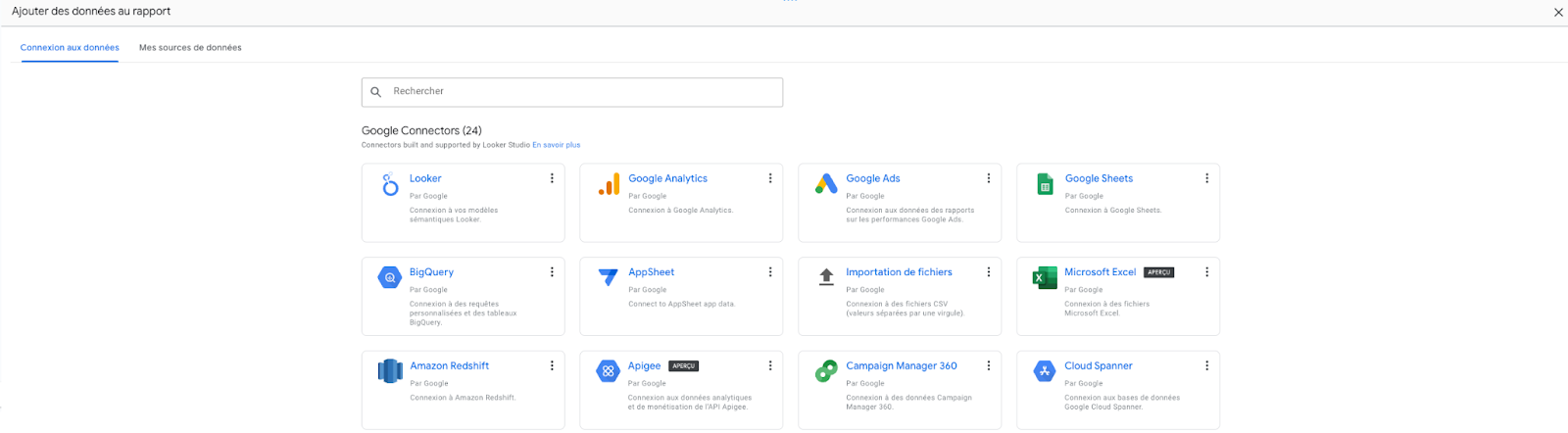
- マイデータソース」にアクセスする。
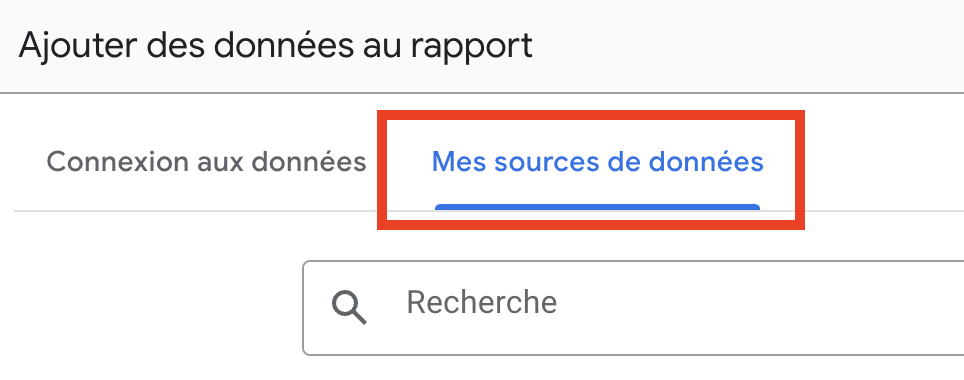
- BigQueryデータソースを追加します。
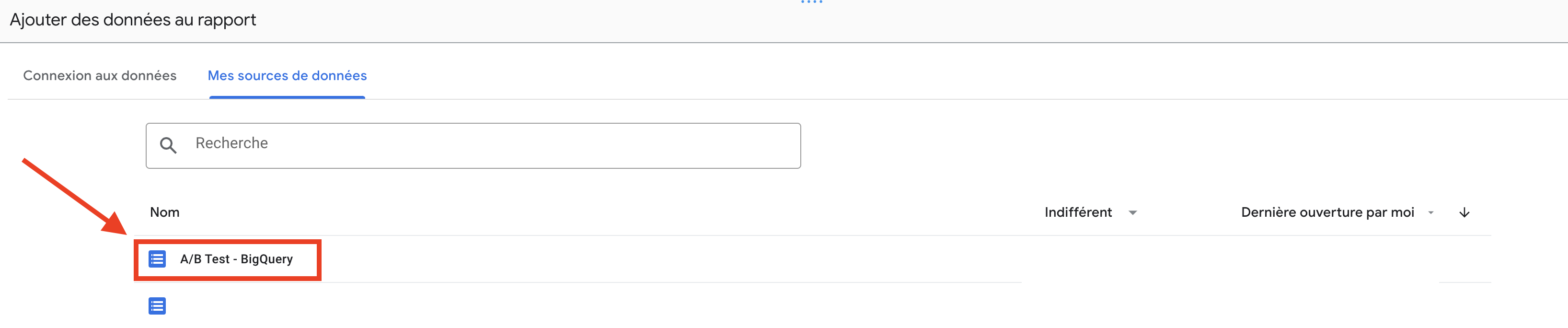
- レポートの左上に、 例えば "Dashboard followed by A/B Test "のように名前を付けます。

- 適切なビジュアライゼーションを挿入して ダッシュボードを作成します。

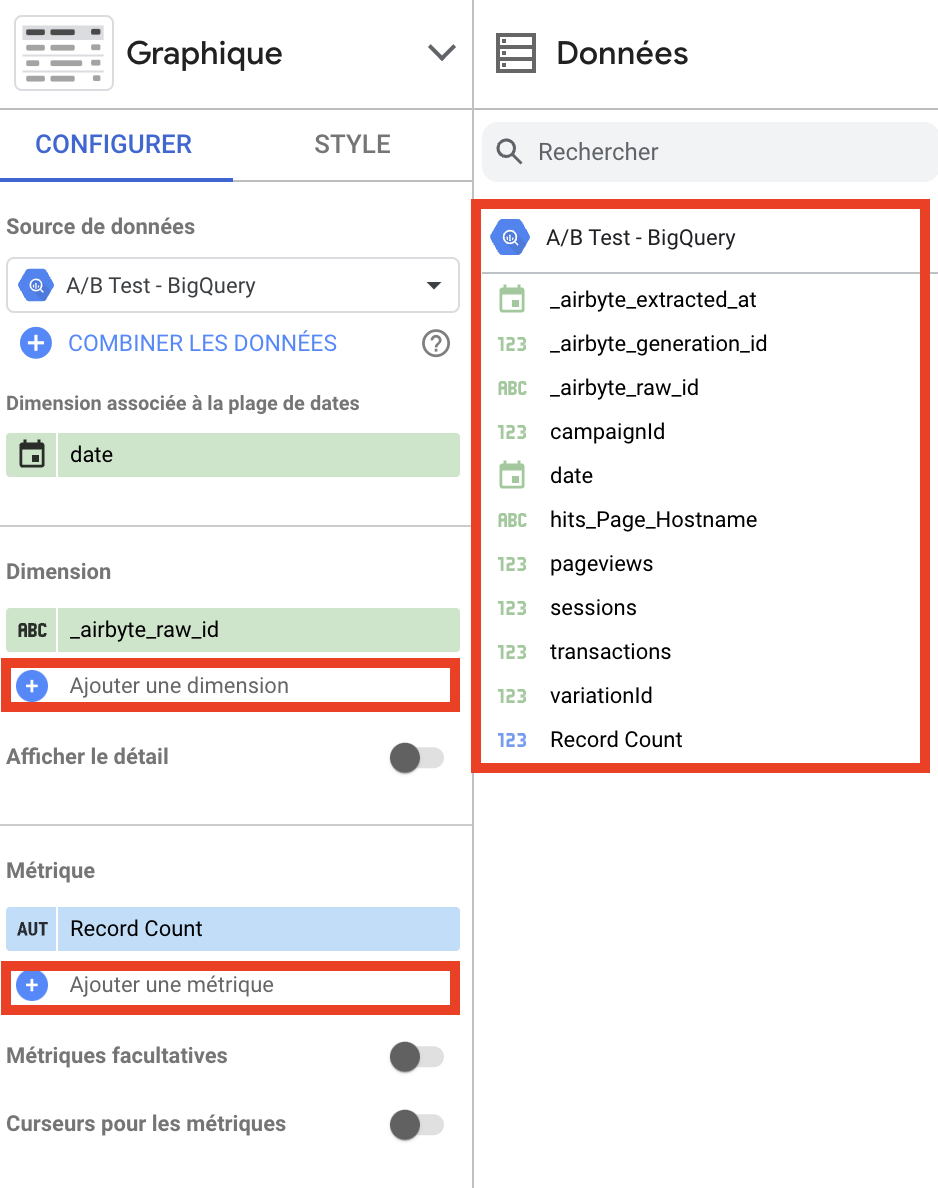
- 寸法と測定基準を追加します。
右側のバナーでビジュアライゼーションをクリックすると、以下が表示されます。
その中で、ソースの下の "data "の右側に、ディメンションとメトリクスのリストがあります。
これらをドラッグ・アンド・ドロップするか、"Add a dimension/metric" をクリックしてビジュアライゼーションに追加することができます。
- ビューのスタイルを設定するには、 ビューをクリックし、「スタイル」ボタンをクリックして、データビズのスタイルをカスタマイズするための設定を表示します。
これで、A/Bテストデータを監視するためのLooker Studioダッシュボードを作成するのに必要なツールが揃いました。


.png)
.png)

.png)
.png)


